2022黑马数据湖架构开发Hudi-应用进阶篇 1
2022黑马数据湖架构开发Hudi-应用进阶篇 1
智汇君2022黑马数据湖架构开发Hudi-应用进阶篇 1
1 | 掌握大数据基础框架安装部署 |
Hudi 应用进阶篇之集成Spark–课程内容大纲和学习目标
1 | 大家好,接下来呢,我们继续来看我们hudi的一个使用,那今天呢,我们来给大家讲hudi的应用进阶篇,那其实我们的第二部分与应用进阶篇当中呢,与我们Spark的集成,在前面我们给大家去讲到了,hudi呢是一个数据湖框架,帮助我们更好的去管理数据,那hudi一开始诞生的时候呢,就是。哎,管理存储在HDFS文件系统上的数据。让我们更好的去管理,那比如说它可以对我们存储在HDF S上的数据呢小文件进行自动的合并。再比如hudi呢,可以啊,使得我们对文件系统上的数据进行一个更新,进行删除。以及我们可以对文件系统的数据,我们进行hudi的这种查询等等等等。好了,hudi一开始诞生呢,就是跟Spark进行集成的。hudi是既不存储数据又不分析数据,就是管理数据,我们需要使用一个分析引擎来进行操作我们的数据,比如说把数据给它放到hudi中去,以及从hudi中呢加载数据,那hudi在进行管理数据的时候跟hive很类似,都是有表的概念,非常类似于我们hive中的分区表。 |
1 | 接下来呢,我们先看与Spark的集成,那Spark集成呢,我们主要从三方面给大家讲。那既然与Spark集成,我们肯定要去准备我们大数据的这种环境,我们知道Spark是分析数据的,我们。hudi呢是管理数据的,那在这里就牵扯到一些东西,比如说我们通过Spark,我们把数据写到我们hudi表中去了,那我们要对这个hudi表的数据分析,我们这时候很可能怎么办呢?我们使用hive来做分析,哎,那我们hive呢,是需要跟我们可以跟我们hudi整合的,hive中的表直接关联到我们hudi中的表就可以了,让hudi来管理数据,Hive呢做分析数据 |
1 | 第二部分呢,我们来通过一个案例,就是滴滴的这种出行数据啊,诶,我们知道hudi这个框架诞生于Uber,它的出行数据,那我们直接用滴滴公开的这个出行数据,哎,海口市的一个数据,我们来做这些处理,首先我们把滴滴的这个数据呢,我们给它进行清洗处理以后呢,写到我们这个。这个hudi表中去,然后呢。我们使用spark做这种批量分析以及使用hive我们来写sql进行查询分析。这第二部分我们来给大家去整合一下 |
1 | 第三部分呢,我们来讲一下结构化流,哎,实时的把我们数据写到hudi表,这种实时的数据入湖操作,这是最常见的一种操作,后面呢,我们还会讲flink怎么实时的把数据入湖。最后我们给大家讲一下在hudi0.9版本当中的新特性,跟我们spark直接集成,我们直接写这种DDL语句,创建表、删除表,以及直接写DML语句插入数据、更新数据,删除数据,包括我们写DQL查询数据,这种操作hudi表的数据。OK,这是我们接下来讲的内容四个方面 |
1 | 那我们主要的一个学术目标呢?六个方面,第一我们要掌握我们这一次内容当中涉及到大数据基础框架的安装部署,其中主要的其实什mysql的安装,Hive的安装部署,zookeeper的安装和我们讲的kafka消息队列的安装,我们都是采用这种伪分布式的单机版安装。 |
大数据环境准备
离线tar安装MySQL 5.7
1 | 接下来呢,我们首先来看一下我们第一部分的内容,我们在讲与spark框架集成的时候,我们要做一些大数据环境的准备。前面我们提到hudi这么一个数据库框架,仅仅来管理数据。好,它从诞生之初就与我们Spark分析引擎呢紧密的进行整合。那我们可以通过Spark这个计算引擎提供的这种data source接口,我们把数据保存到hudi表中去,哎,我们也可以呢,使用Spark从hudi表中呢加载数据进行分析。 |
1 | 安装MySQL 5.7 |
1 | 好,那接下来呢,我们首先来去安装这些软件,那安装软件当中呢,那先呢,我们来安装一下mysql这么一个数据库,那在mysql的安装有很多种方式,我们可以在线。通过RPM安装也可以离线安装,那在这里呢,我们通过一个简单的方式,通过tar解压方式来安装,OK,好了,这里面有完整的步骤,我们按照步骤操作就行了,OK,那首先我们来看一下啊,我们来切换一下在这边。好,那我们首先呢,我们采用tar的方式安装mysql数据库 |
检查系统是否安装过mysql
1 | 命令在这首先我们检查我们这个系统有没有装过mysql数据库来执行一下rpm -qa|grep mysql。如果装过的话呢,我们首先要把它给卸载掉,然后再进行安装好,同学们看到这里是没有的,紧接着我们继续往下走。 |
卸载 Centos7 系统自带mariadb
1 | 好,然后呢,我们卸载掉我们CentoS7呢自带的mariadb啊,这是跟mysql数据库类似的,好,那我们把它给卸载掉啊,我们卸载掉OK。好,那我们就是rpm -qa|grep mariadb的把这个mariadb给它卸载掉。 |
删除etc目录下的my.cnf ,一定要删掉,等下再重新建
1 | 好,卸载掉完以后,我们最好呢,把mysql数据库相关的一些配置文件给它删掉,那有一个配置文件呢,我们知道它是在我们讲的这个系统的/etc目录下面啊,往往有一个my.cnf这个配置文件一定要删掉啊,不然的话就会报错我们后面安装。 |
创建 mysql用户组和用户
1 | 好,紧接着我们安装mysql数据库呢?我们需要去干嘛呢?创建一个mysql这么一个用户组和用户,OK,那接下来我们来执行命令。好,这个比较简单,我们group添加,在系统添加一个组,名称就叫mysql,groupadd mysql。然后呢,我们添加一个用户useradd -r -g mysql mysql,指定MYC,这个用户的用户组叫mysql,然后呢用户名称叫mysql,这样的话呢,我们就创建好了 |
解压安装 mysql
1 | 紧接着呢,我们需要去下载mysql包,wget url,我给大家已经已经提前下载好了,我们直接呢进行上传就可以了。然后我们进行解压安装啊,tar进行解压就可以了,这种方式是最简单的方式,同学们啊,OK,那我们在企业的生产环境中呢,我们往往也采用这种方式,tar包安装非常的简单啊。避免我们什么在线啊下载等等的东西。好,解压完以后呢,我们来看一下这个目录是比较长的,是不是我们直接给它改掉,我们不需要那么长的名称。好,然后同学们可以看到这个包啊,它的一个用户名和用户组啊,它不属于我们什么呢?不属于我们root是不是啊,我们可以进行修改,可改成root也可以不修改啊好,那我们修改一下吧,chown -R root:root mysql/。 |
编译安装并初始化 mysql,务必记住数据库管理员临时密码
1 | 好,呃,那紧接着我们继续往下操作。然后呢,我们进入到这个mysql目录下面有一个什么呢?有个bin目录,同学们啊,里面呢,有很多脚本,其中有个mysqld。好,那我们运行这个脚本呢,我们进行初始化的操作,mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql,在这啊后面加上这么一串啊,初始化设置,我们的初始用户mysql,我们的数据存储目录叫data,我们的基础目录叫mysql.好,同学们,我们来回车执行一下。啊,如果有问题,咱们再去修改啊。好啦,呃,这样的话呢,我们整个呢,就给大家去做完了啊。 |
编写配置文件 my.cnf ,并添加配置
1 | 那做完以后,紧接着我们要去编辑一下啊,叫在我们叫做/etc/下面有个my.cnf文件mysql的配置文件啊,然后呢,我们进行加上以下配置。直接copy一下就可以了 |
启动mysql服务器
1 | 接下来我们就可以启动我们的数据库了,启动数据库。呃,启动数据库呢,也是比较简单的,/mysql/support-files/mysql.server start,咱们来启动。可以看到啊,这里面有个什么success,那这里面如果启动包异常的话呢,这里面有个日志,我们可以稍微的去看一下这个文件。好,同学们看这里面没有报错,只是告诉我们这个密码叫什么3306是不是啊。 |
添加软连接,并重启 mysql 服务
1 | 启动完以后啊,我们要添加软链接,然后呢,再重启我们的服务,以后我们启动就不用麻烦了。ln -s /mysql/support-files/mysql.server /etc/init.d/mysql ln -s /mysql/bin/mysql /usr/bin/mysql,service mysql restart大家看这里面已经说我们重启成功了 |
修改初始密码
1 | 重启成功以后。我们来登录mysql,mysql -uroot -p输入我们初始化的一个密码。那初始化密码在哪里呢?。密码就是我们初始化生成的临时密码,在哪呢?,在我们启动的时候,应该会告诉我们有一个初始化的密码。我们在进行初始化的时候,其实这里有个密码,同学们要注意啊。进来以后我们要去设置一下我们的密码叫 set password for root@localhost = password('123456')。好,这样的话呢,我们就设置好了 |
开放远程连接
1 | 设置好以后我们来use mysql这个数据库,然后呢,我们要进行更新update user set user.Host = '%' where user.User = 'root'.好,执行完以后我们进行flash刷新一下啊。哎,我们来刷新一下这个权限flush priviledges。 |
开机自启
1 | 做完以后,紧接着同学们,我们基本上就设置完成了,我们可以退出了。退出以后,我们来设置一个我们数据库随机启动啊,,随着我们这个开机进行启动,好这里面我们得稍微设置一下啊在这。cp /mysql/support-files/mysql.server /etc/init.d/mysqld |
客户端远程链接数据库
1 | 那紧接着呢,我们来通过客户端链接一下,好,我们就使用我们这个idea来链接一下,那在这里面idea这里面有一个database数据库,咱们创建一个mysql链接。。。。好,那我们看一下这个驱动包。哎,我们就用它就可以啦,然后我们测试一下啊测试一下。我们看能不能连接到我们的数据库,没有问题的,对不对,apply连接。在数据库中我们看到的这个user用户这张表,刚才其实我们更新了它的权限啊,我们看一下来看我们是不是更新了root。呃,它的主机任意的主机OK,那这样的话呢,我们整个mysql数据库呢,我们就安装完成了,OK. |
安装部署Hive
1 | 这里我按照大数据开发工程师hive篇来的,注意在配置hive-site.xml时,那个ip是使用vmnet8的ip,不是我主机的ip |
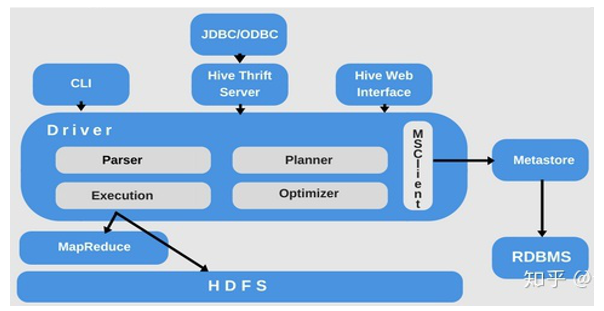
1 | 那我们把马赛克数据库安装好了,接下来呢,我们来安装hive。那hive呢,我们都知道是大数据当中的数仓的这么一个工具框架啊,帮我们去管理数据的,按照分层的架构去管理。以及呢,我们可以使用呢hive呢来写语句,它默认的把sql转换成mapreduce来处理HDFS数据,在企业中呢,基本上我们都会用hive。啊,哪怕我们用hive来管理原数据,我们用Spark分析或者用flink分析好,那hive的安装呢,也是比较简单的,我们直接解压hive框架的tar包,配置HDFS依赖和原数据mysql数据库信息,最后呢,我们启动它的原数据hvie metastore和hiveServer2服务就可以了。 |
首先、解压tar包和设置环境变量
1 | 好,HDFS,我们已经配置好了,mysql已经做好了,接下来我们来装hive。安装也是比较简单的,就是解压上传配置环境变量就可以了。好在这里呢,这个软件呢,我给大家提供了在这啊,那接下来呢,我们来上传进行操作一下。然后呢,我们给他一个执行权限chmod u+x hive.tar。解压完以后,我们呢,要给它重命名。并且呢,我们创建一个软链接,我们整个hive呢,就安装好了 |
其次、创建HDFS目录和配置Hive属性
1 | 配置完以后,我们要先干嘛呢?启动我们HDFS的这个服务,好启动HDFS服务啊。namenode然后呢,我们再启动一下nodenode。好,启动完以后,我们稍等片刻,稍等片刻啊OK。我们等到安全模式结束以后,我们再去。启动啊,再去创建目录。那我们可以呢,通过50070,我们进行查看这个界面啊查看。我们可以看一下这个界面啊,目前还是安全模式,我们稍等几秒钟。创建这个目录 |
配置hive-site.xml属性
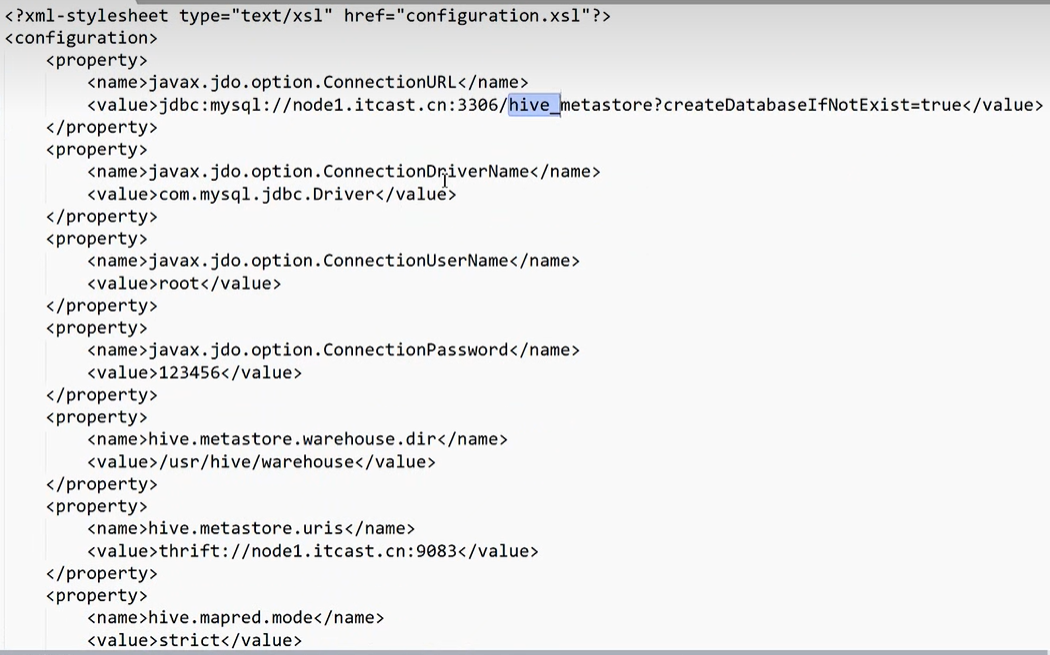
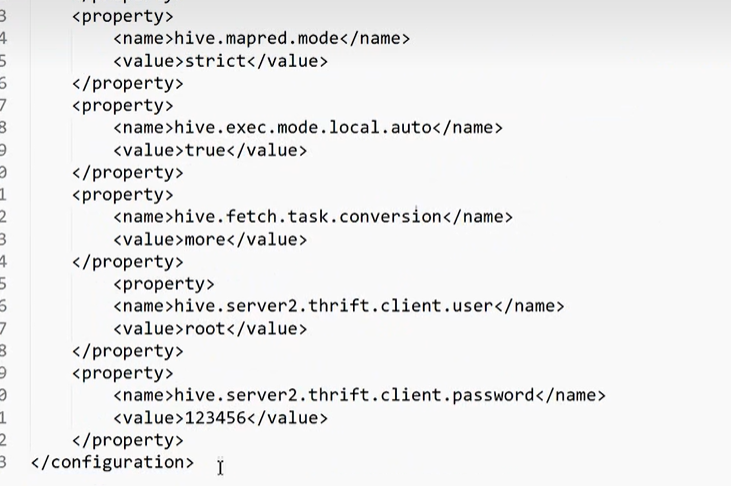
1 | 在这里面我们可以看到,这就是一个我们说了我们的这个mysql数据库所在的地址,这下面还有一些其他的东西啊,mysql驱动,以及我们root,用户名,密码,以及我们讲的存储目录,包括我们metastore的地址,以及我们讲的其他一些属性配置。 |
再者、添加用户权限hadoop

1 | 好配置完成以后,紧接着我们再做一件事情,我们要去看一下我们的这个hadoop中啊core-site.xml,添加这种哎,权限配置,我们看有没有配置。 |
初始化数据库和启动MetaStore服务
1 | 好,配好以后,紧接着我们要进行初始化我们的数据库,同学们。那这时候呢,我们首先要把我们在我们的hive的内部目录下面放入mysql的驱动包mysql-connector-java-xxx.jar,这驱动包呢,在这我们直接放到hive的内部目录下就可以了。 |
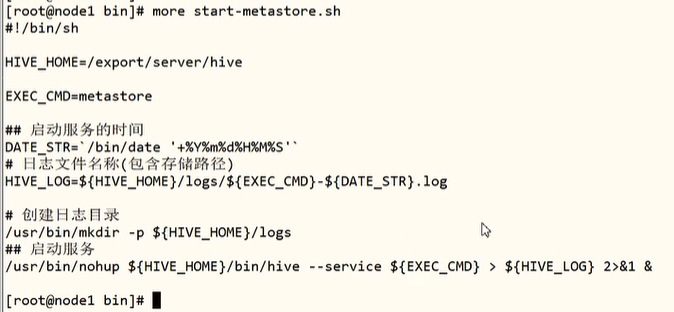
启动HiveServer2服务和beeline命令行
1 | 做完以后,紧接着第7步,我们来启动我们的什么呢?hivemetastore服务。那我们可以直接启启动这个命令bin/hive --service metastore >/dev/null &(大数据开发工程师哪里没有这个启动metastore服务啊,只有初始化),我们也可以写脚本啊,包括我们在启动hiveserver服务是一样的/bin/hive --service hiveserver2 >/dev/null & |
1 | 我们再去启动我们的服务啊,就是哎,start-metastore.sh |
使用beeline客户端连接
1 | 啊,当启动完成以后,我们去启动什么呢?beeline,我们来进行一个链接,我们来试一下看能不能连接成功bin/beeline -u jdbc:hive2://bigdata04:10000 -n root -p 123456,同学们啊。好了,这是我们稍微等一下。因为这是比较慢的啊,大家看已经链接上去了,那这时候我们来看一下我们这个hive呢,hive中呢是没有表的啊,是没有表的,那我们show databases,它只有一个什么呢?default。这数据库里面呢,也没有表好 |
安装部署Zookeeper
1 | 接下来呢,我们来安装另外一个就是keep。那鲁keep这个框架呢,我们后面卡夫卡需要依赖,包括我们后面讲我们的护地与冯定的集成,我们进行实时的数据入库的时候都要用到卡夫卡,那卡夫卡呢,又依赖于我们组keep协作框架,组keep的安装呢非常简单。我们说keep是阿尔法奇顶级项目啊,它是为分布式的应用呢,提供高效高可用的分布式的这种协调服务,我们很多很多的框架都依赖于它,比如说HDFS的高可用,我们resource manage的高可用,H数据库卡不卡等等等等都依赖于它。那如K呢,要求我们的集群呢,是基数的,在整个集群决算当中呢,有need和follow need主要是用于对外进行什么呢?提供这种服务的,写数据的那。Follow呢,可以进行读数据的,我们所有的follow都跟need来进行同步,好了,接下来呢,我们来进行安装一下,我们是单机版的,安装也是很简单,我们首先进入到我们安装目录下面去,然后呢我们进行安装就可以了。好,然后呢,这里面呢,我先退出,同学们我们先退出。好,然后呢,我们先看到我们的export上下面去,然后呢,我们去上传我们这个软件包。软件包呢,这里面我们给大家已经放好了,放在这下面叫做keep。好,我们直接给他上传就可以了。上传完以后,我们直接呢进行挤压,同学们首先呢,给他一个执行权限啊。好,然后呢,我们解压一下吧,他包解压一下theper。解压完成以后,同学们,我们可以看到我们来创建软件机,这个用户有点不对,我们稍微变一下啊。OK,我们把它改成root好吧。好,然后呢,我们创建一个软件接啊,创建这么一个软件接。音节的话呢,N读keeper,我们就叫读keeper。好,并且我们删除这个软件包,把软件删掉没什么用,对吧?好,这样的话呢,我们整个就装好了,同学们我们可以看一下,此时我们已经把如keep给它解压完成了。解压完成以后,我们要进行简单的配置,进入到组keep的客服目录下面,我们进行配置,配置的数据的一个存储目录,OK.好,进入到目录下面去,同学们。接入以后,我们进入到看膜的下面,那这里面有个入杠Z。Sample这个配置文件改个名称,同学们啊,CFG改完以后我们来进行写一下,在这里面呢,我们把这个数据的存储目录呢,我们稍微改一下啊,不用这个目录,我们改成一个我们的目录。在这里面比较简单一点好,我们到export serve keep群,我们创建一个目录,我们叫做data目录,然后我们进拷贝一下这个目录export。S keepa data字目录,那我们数据放这里面,这样的话呢,我们整个就配置完成了。配置完成以后,同学们我们来再做一个事情,我们来配置环境变量,方便呢我们进行使用。好,在这里面我们看一下环境变量呢,在这OK,同学们啊,我们来看一下。那。回撤一下,我们在最后的话去添加,就是我们讲的look keepper home,对吧,还有我们X hot,哎,Z look z.Z go home对吧?配置一个这么一个home。好,紧接着呢,我们往下看。这是我们所讲的。好,那我们保存一下,同学们保存下来。保存完以后呢,这样的话呢,我们就配置好了,OK,我们就可以启动我们的服务了,在这里我们再做一个稍微的配置。啊,做个什么配置呢?同学们我们看一下exportva keep,在zoo keep这个B音目录下,同学们有一个脚本,我们稍微修改一下,这个脚本叫vim z k EV这个DSH脚本在这个脚本当中啊,我们去设置一个路径啊设置个什么路径呢?就是我们启动组keep的时候,它的日志的一个目录,这个目录如果你不设置的话,你在哪启动就在哪目录下面,这是不好的啊。好,我们把它设置一个值。设置什么值呢?同学们看一下就设置我们在做keep下面。啊,再组Q项你就可以了。好在组题下面,好在这里面呢,我们可以起创建一个目录啊,创建目录OK,在这我们退出make DR-P杠什么呢?Locks好P没底。好,同学们,这样的话呢,我们启动组keep在任何启动它的这个日志上都在log字母上去,好,那这样的话我们SRC,然后呢,我们来启动组keep就可以了啊,Profile使得生效。我们来启动,启动比较简单,哎,我们可以直接打,哎,就是z can什么start。好,启动完以后呢,我们再打一个四四同学们这是不是单的,那我们单机版配置的OK,那这样的话呢,我们整个组K版呢,就给它启动好了。 |
安装部署Kafka
1 | 哎,那5K版安装好以后呢,我们来安装我们的这个分布式消息对联卡夫卡,我们用的是2.4版本。那我们知道卡夫卡最初呢,由拟音公司开发的,它是一个分布式的,分区的,多副本的,多订阅的一个。消息系统。但是它依赖于一种keep,那最新的版本当中它是不依赖于的啊,那卡不卡呢?常常用于于用于我们网站的web和INS服务器日志的一个缓存存储。它早已是阿帕奇顶级项目了,我们只要做牛市的实时计算,基本上我们都会用到组K,卡不卡,卡卡呢依赖于我们讲的组keep集群,OK,它这里面的数据呢,是放在一个topic当中的,Topic划分成很多分区,每个分区呢有多个副本。好,接下来呢,我们来安装一下卡不卡也是比较简单的啊,那这里呢,我们的软件呢,也给大家呢准备好了,在我们这一个目录下面,大家可以看到这里面有一个叫做卡夫卡2.4的版本,基于盖2.12版本的。好,接下来呢,我们来安装一下同学们,那首先呢,我们进入到EXPORT4部下面去,然后呢,我们来上传同学们。上传完以后,我们来进行解压啊,进行解压。OK,那首先我们change mode啊change mode的话呢,我们给他一个权限。然后呢,我们踏包进行解压,踏包解压。好,解压完成以后,我们呢,看一下这个目录OK啊看垂线。好像是没有什么问题的,对不对,卡不卡,那在这里面呢,我们创建一个软件接啊卡不卡,那我们就要卡不卡对吧,删除我们这个卡夫卡的什么呢?卡包。淘啊淘宝好筛,然后呢,我们进入到卡夫卡的这个。目录配置目录叫con目录,同学们我们看一下con目录啊,那在con目录下面呢,我们可以看到它有些配置,我们来进行修改。好,同学们,我们来看一下配置在哪里呢?好,我们看一下。在这里面修改内容呢,比较简单。那首先其实就是一个监听地址,一个就是我们的卡夫卡的数据存储地址,一个依赖一种keep的地址,好,我们只修改这3个地方就可以了。好,我们修改一下VM不好,我们看多少行,同学们往下走,那这个第一个这是broke ID,我们不用改,这个我们稍微改一下,同学们啊,稍微改一下。然后呢,这里面我们写上这个地址就可以了啊,我们这是node e it cost.c好再往下走。下面这个呢,我们也不用改什么东西啊,不用改。好之后注意这个路径我们得改一下,同学们。这是我们存储的数据的一个路径啊。好,这是我们讲卡夫卡的一个消息队列,对不对,我们创建这目录,好,我们到卡夫卡中去,同学们啊,然后呢,我们麦D到T创建这么一个路径。嗯。同学们,我们写错了,我们不应该写,写个杠,把杠给去掉,好进入到卡夫卡的客服下面下去,我们。PWD查看我们的这个卡夫卡的最终消息存储的这个。磁盘的一个位置。好,这样配完以后我们继续往下走,一直走到最后,同学们。我们要做最后干嘛呢?我们要去做一些事情,就是我们依赖的keep的一个地址,Keep地址啊,以及我们在keep上node的位置,阿卡点C。好,那我们一对1就什么呢?就叫做卡卡。看不看啊,那这样的话呢,我们整个配置呢,就完成了,同学们。诶。A少了一个A对吧,少了一个L不能写错啊。好,我们保存下来。保存完以后,我们要设置一下环境变量,同学们。那卡va的环境变量呢,设置起来也是比较简单的,同学们啊,我们看一下m ETC profile.好,我们看一下profile。好,我们在下面来设置一下来,我们说卡不卡的一个home export卡不卡home等于。OK,我们的安装目录。好在这里面呢,我们copy一下,就是我们讲的卡不卡啊。好,配置完成以后,我们来进行source一下,使得我们配置生效投入发扬好,然后呢,我们接下来呢,我们就可以去启动我们这个服务了啊。那服务启动也是比较简单的,同学们我们看一下那卡不卡,然后呢,我们说server start,哎,我们放在后台启动,是不是后台启动,然后呢,我们就指定一下export star卡卡con下面的什么呢?Star practice.然后启动,然后我们打个勾,同学们看一下勾。那个S这里面我们可以看到卡夫卡这个节点,那在这里给大家介绍个工具,一个叫什么呢?卡夫卡two的工具。这个工具呢,很好用,去链接我们的卡夫卡啊。好,同学们,我们来看一下,在这里面我们可以给它创建一个,创建一个新的链接。好,这个名称呢,我们叫忽底杠卡夫卡对吧。而在这里面,我们卡卡的版本是2.4OK,是在我们NOE1这台机器上面的啊,这个地址其实是我们keep的地址,后面有个卡普卡对吧。来,我们添加测试一下。同学们,我们看一下啊。那这样的话呢,我们创建topic,查看topic数据呢,就比较方便了啊,我们直接在这个工具已经链接成功了,同学们我们双击一下。好,那目前呢,是没有topic的,对不对,什么都没有的,只有一台机器。OK,那这样的话呢,此时我们卡夫卡去安装完成呢,安装完成以后,我们就可以往卡夫卡消息对面写数据了,我们也从可以从卡夫卡怎么样呢消费数据进行处理了。OK,那此时呢,我们整个大数据的这个环境就给他准备好了,那后面呢,我们就要开展讲,以从应用的角度,实战的角度来讲,我们。Whodi与Spark整合的一个使用啊,我们批量的把数据加载到互Di表中去,批量从互利表中读数据,以及我们与have与互Di表集成来分析互理表数据,包括我们结构化流实时统卡卡消费数据,并且把数据写到互理表,以及我们进行一个查询分析。OK. |
滴滴运营分析
集成Hive查询
1 | 前面呢,我们讲到了,直接从hudi表里面呢加载数据,然后进行指标分析,接下来呢,我们稍微的变换一下,我们说了,当我们把数据存到hudi表以后,我们还可以与我们的hive进行集成来做分析。好,接下来我们看一下,我们就把我们前面刚才讲的这个滴滴的出行的这个数据在hudi表中的,对不对,分区存储,我们给它呢,映射到我们hive表中。哎,我们从hive表中呢来编写sql进行查询,哎,这也是可以的,好,接下来呢,我们来进行看一下怎么去完成,那这时候呢,我们就要涉及到hive与我们hudi表的集成,那这时候呢,我们需要使用到一个jar包,在我们前面编译完hudi的这个。安装目录下面其实有个hudi和hudi-hadoop-mr-bundle-xxx.jar的这么一个jar包,我们直接把这个jar包呢放到我们hive的lib目录下就可以了,那我们拷贝依赖包到hive的路径下面,为了我们hive能够正常的读取到这个数据。啊,那拷贝完以后,同学们不要急着去操作,我们要把我们的hive的服务给它重启一下。那这样的话呢,我们整个呃,集成就配置好了啊,就是一个架包对吧,没有其他东西。 |
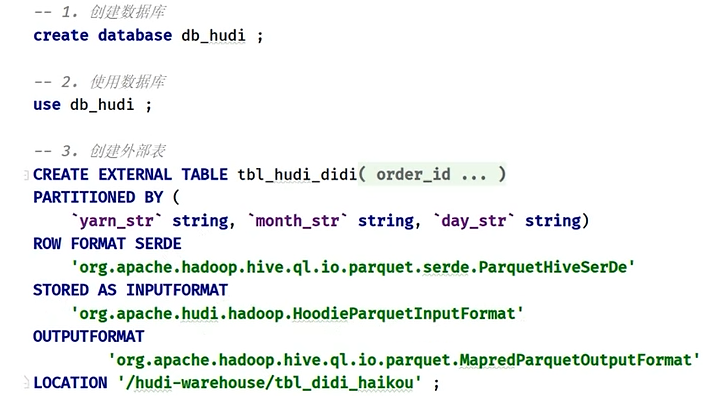
1 | 好配置完以后呢,紧接着呢,我们就需要呢,在have的命令行呢,我们要创建表了。把我们讲的滴滴出行的这个表呢,映射到have表中去啊,在这里面呢,我们创建have表呢,是属于一个外部表。它基本的语句是这样,大家看创建一个表是不是correct table,创建一个数据库叫DB,然后呢,我们使用数据库在这里面创建一个表,这是一个exterunnal,一个外部表,然后呢,这里面是字段,那在这里面我们要注意一下啊,我们在这里存储的时候呢,要加一个分区。好,我们呢,刚才在存储数据,我们分区其实只有一列,就日期分区,对不对,我们就写一个一个分区,那在这里面我们要指定一个什么东西呢?同学们看,就是我们数据的存储格式叫stored are the input format,注意它是who pack input format.我们时代存储在互利表中,并且是pack列式存储,最后呢,我们得指定location,其实就是我们数据的存储的一个路径就可以了,啊,这比较简单的好,那接下来呢,我们切过来。呃,这边呢,同学们,我们昨天呢,在讲这个idea的时候呢,其实我们已经配置了我们的这个have对吧,Have同学们看在这。好了,我们双击链接一下啊,让让他去呢,链接一下。知道吧,我们去链接一下OK。好,我们看一下吧。好,同学们,我们来选择所有的。OK,我们来链接一下啊,链接一下我们have。嗯。穿的面看链接完成以后呢,我们在这里编写我们的语句啊,编写我们的语句。好,比较慢,稍等片刻。这应该是可以链接的啊,我们看一下。GPS.好,应该是没有问题的。呃。我们看一下好了没有。因为我们have,昨天安装好以后呢,我们没有去写数据对不对。链接。好,成功以后呢,同学们,我们在这里面打开一个。终端打开一个终端啊,打开终端。好,打开终端以后呢,同学们我们来看一下,在这里面我们可以去写一下,我们在这里写写我们的数据。好,这个呢,我先把它。在这里面,那首先我们刚才讲的第一步,我们来创建一个数据库database,好同学们我们看一下啊,Create,我们说database对吧,If如果不存在的话,我们创建,而这数据库呢,我们叫做湖底可不可以啊。好,第二步呢,我们来使用这个数据库,对吧,使用啊,使用这个数据库,那叫什么use。右侧的话DB互利对吧。好,我把这个呢给大家执行一下来,我们看一下走。好,这边我们来看一下这个数据库。好,大家看是不是多了一个,然后呢,我们来使用这个数据库使用啊。好。使用咱们这个数据库。这个。使用对吧,使用结束了啊。那接下来第三步,同学们,我们都知道创建表是不是好,我们看一下啊,创建我们的表,创建我们的表,那我们说过了,Create创建的是一个什么表呢?外部表。Table是不是if not不存在,我们的创建是不是?好,这个表呢,我们叫table杠什么呢?忽底杠DD可不可以啊,那这里面是不是咱们字段名称啊。好,那这字段名称的同学们,我们呢直接呢给大家copy一下啊,这字段比较多啊,我们写的也比较慢。杭州自然名称,OK?好同学们,这个呢是非常简单的,就是我们这个表里面有多少字呢,我们就写多少字呢。给同学们贴上去,我给它贴过来,好,我们调整一下格式。调整格式啊。好,类型要对上同学们啊,对上,那第一个就是我们讲的订单ID,然后产品ID等等,那这是我们讲的分区路径,以及这这些字段,好紧接着呢,同学们注意,这里面我们需要加上一个什么呢?叫partition的BY。好,这里面我们说这个类型,我们得加上一下。那在这里面我们其实就是一个日期STR。它的类型我们叫什么呢?叫子串。对不对,周长好,那接下来呢,有几个大家注意一下,同学们,就是我们讲的这个文件的这种格式。啊,注意这是固定的,我直接贴过来啊,在这第一个我们的room format,我们的这种存储,其实我们说我们说这个是一个什么,是一个pack劣势存储对不对,那input me我们是存储在什么呢?忽底表当中的,对吧。那我们的输出格式也是pack好,这是我们的数据的存储路径,要注意就是存储路径我们是在大家看好了,在who d we are house下面,Table滴滴海口下面是不是好,这样的话整个表就创建好了,那咱们这是一个分区表,同学们注意。好,我们执行一下这一下啊,执行完以后呢,我们打开看看这个分区表创建好了。那既然是分区表的话,同学们都知道,我们看一下,我们可以是查看。啊,查看分区表的这个分区,分区表的这种分区。啊分区,那我们说这里面有一个命令叫修。帕选4是不是这种表的名称啊,好,那咱们这个表的名称呢,叫DBWHO底点。是不是我们的我们的table啊,OK,搞定。好了,我们看有没有分区啊,现在是没有分区的,对不对。好,同学们现在是没有的是吧,那但是同学们来看一下我们这个数据,我们看一下啊,我们是有的,有多少个20个分区。那咱们是不是要手动添加分区啊好,那紧接着呢,我们做一件事,就是我们讲的,哎,手动的我们要去添加这个什么呢?分区信息。添加分区信息,好,同学们,那添加分区呢,这个命令大家会去写啊,我们来写一下叫al。什么呢?Terrible是不是?好,我们说DB whodi.table who底是不是,然后and。啊,If not,如果不存在的话,我们添加分区。好同学们,这个呢,就是我们讲的叫,哎,我们讲的这个字段值,好这个字段值呢,我们要注意一下,那这里面的值值我们知道这是从5月份开始,对不对。5暂开始。好,那咱们就一直往下添加。啊,把它添加完成,并且在后面我们要去指定一个字段叫什么呢?Location是不是我们的数据的位置啊location。好,数据位置呢,我们指定一下同学们,这是我们讲完整的,那整个数据的位置我们看一下是在这个目录下面,同学们注意啊。设置中控下面叫什么呢?这个路径下面的数据对吧。整顿下面,诶在后面同学们啊。在这里面我们稍微看一下,你看点进去嘛,这是不是个路径啊,整个路径,整个路径啊。好,这样的话呢,我们需要去添加20个这么一个东西,好,那我们一个写。三四五六七八九十一二三四五六七八。钱不多。好,我们说从多少方呢?从二十三,二十二号,23242526,二七二八二九三十三十一。好,这是23。这是二十四,二十五,二十六,二十七,二十八。29。然后是不是30啊,30以及什么三十一没问题。好,那我们再看,那第二个呢,其实就是我们6月份的,6月份从从几号开始。从1号开始,一直到10号。注意同学们,这前面没有0啊,没有零啊,这个6对吧,2017年6月1号对吧,6月1号啊,6月1号。好,咱们写下一二号,3号4号,5号,6号,7号,8号,9号10号。好,我们写一下2号3号4号5号6号7号8号9号10号对吧。好,最后一个呢,重复掉了,在这里大家千万不要忘记了,我们后面这路径也得改是不是对吧,二十三二十四。25。26。对吧,二十七二十八二十九三十。好,有人说了,老师啊,这有没有工具呢?有工具啊,那在这里面我们就采用最简单的方式来做好吧,那这其实就是我们讲6。这样我一一嗦一说把它改掉啊。然后呢,这是我们讲什么呢。OK.嗯。1。这说明234567。8。举同学们啊。最后是咱们讲什么呢,10。那10的话呢,这是6月份6月10号,那这样的话呢,我们整个10个分区呢,我们给它手动添加上去。好,同学们,我们来执行一下10个分区。好,给他执行。OK.总共有20个分区,对不对。5月份10个,我们6月份10个。好,整个呢,执行完成以后呢,同学们我们再修一下,看一下多少个分区。大概分区是不是有了。好,有了以后,紧接着咱们别忙着进行分析,进行分析,咱们首先来进行查询一下数据。好,咱们测试。好,我们进行测试,我们来查询数据啊,测试我们查询我们的数据,好,同学们,我们来看一下select,然后呢,From DB护理,OK.好,这里面这个数据呢,我们不要查那么多,我们首先查一个订单的ID。订单ID啊,然后呢,我们查一下叫做我们说这有个叫产品的ID,是不是产品ID啊,OK,我们说有一个类型有一个。预支的一个费用,是不是还有一个我们叫做交通的类型是吧,还有一个我们叫做距离叫distance。Distance.啊,就是距离。好,那今天呢,我们来查询一下这个数据,我们不需要太多,我们查询啊,20条就可以了,同学们。好,那在这里呢,我们把这条语句选起来,我们来执行一下,看结果,同学们啊。好了,呃,同学们,我们可以看到啊,这里面讲到了一点啊,我说我们说我们当前的模式,什么模式啊,严格模式OK,好严格模式我们不加分区呢,它会出错的,好所以我们先设置一下吧。我给他报了一个错,就是严格模式。好,我们设置为什么呢呢。A strict就可以了。好,我先设置。好,然后呢,我们再去执行。好,再去执行的话,大家可以看到数据是不是查出来了,查出来了这是我们用这个工具非常好用,大家可以看到啊。这是我们完整的一个结果,同学们可以看到吧?好了,这是我们所讲的,那接下来呢,我们就可以在这上面我们写思考来进行什么啊,进行我们的这种指标的这种统计分析了。OK.好,这是我们讲的have与互利表的一个集成,首先就是创建表,创建表的时候要注意啊,因为我们是分区目录,指定分析字段,以及我们下面这几个属性,我们就是统一的,这样去配置就可以了,最后呢,我们手动的添加这个分区,OK,那刚才说过了,我们一定要去设置一些非严格模式,然后再去查数据,看一下结果。OK,那集成完成以后呢,那咱们呢,就可以继续来去写我们的代码了,来做我们的这种分析报告了,啊,做我们的分 |
结构化流写入Hudi
集成 SparkSQL–快速体验数据CRUD
1 | ppt 100页 |
启动服务
1 | 接下来呢,我们看另外一个知识点啊,也跟我们Spark相关,跟我们护底的这种集成,是在hudi的最新版本0.9版本当中呢,提供的与我们Spark sql集成,说白了就是我们可以在Spark提供的Spark sql交互式命令行呢,我们直接可以写这种sql语句来关联我们hudi表的数据,来对hudi表进行增删改查操作。 |
设置参数
1 | 这样的话呢,就启动我们一个Spark sql的这么一个交互式命令了。在这里面我们来进行一个操作啊。OK.好,稍等片刻啊,稍等。好,启动完以后呢,我们可以打个show databases,默认情况下,其实我们这个数据库啊,它只有一个default数据库,对不对,没有其他数据库。好,启动完以后。紧接着在这里面我们得设置几个属性,因为我们对互利操作的时候,在spark命令行你是插入数据,更新数据,删除数据的,默认它的这个并行度啊为1500,太大了,我们把这数据呢给它设置小一点,同学们设置为几呢?设置为1。好三个呢,设置完以后,一个是upsert,一个是insert,一个delete,设置完以后,紧接着呢,我们要设置一下同步不同步我们hudi表的原数据啊,是不同步的啊 |
创建表
1 | 这4个属性设置完以后,我们就准备好了,接下来呢,我们就可以去使用了。好,接下来我们看一下怎么去用啊,这个也是比较简单的。好,那紧接着呢,我们往下走,那首先呢,我们来创建这么一张表啊,我们编写一个DDL语句。那我们创建一张表呢,关联到我们hudi表中去 |
插入数据
1 | 好,我们一次性多插几条数据进去。好,我们给他执行。大家稍等片刻。啊,这个比较慢,我们先不管它,其实我们这个表中有几条数据了,有4条数据。好,同学们紧接着往下看,接下来呢,我们来从这个表里查数据,我们select * from。这就是我们所讲的,这是用spark sql来进行操作我们数据的。那此时我们可以看一下我们这个表的这个结构desc |
更新
1 | 当数据查询完以后呢?我们还可以干什么呢?我们还可以进行更新数据,同学们,更新数据,更新数据就是我们讲的标准的这种语句Update。比如说我们更新一个表,Update test_hudi_table set price = 100.0 where id=1,这就是更新语句啊 |
删除
1 | 好,当然我们这里面还可以怎么样呢。我们还可以删除数据,那就是delete from test_hudi_table where id=1,我们再去查一这条数据,我们看能不能查到,同学们看一下。有没有数据啊,没有数据已经查不到了,因为这条数据是不是被我们删除掉了,OK,被我们删掉了,好,这是我们讲的这个hudi跟我们支持spark sql写这种DDL要语句和我们讲的插入更新删除查询的语句,非常的方便。好,这个功能呢,我们要知道一下有这功能OK。 |









